Count Models
This page discusses why count models are necessary in certain applications, and discusses beginning details of the Poisson, negative binomial, and hurdle models.
# Continuous versus count outcomes
Typical regression models are aimed at predicting the
response of an outcome variable
This regression framework assumes that
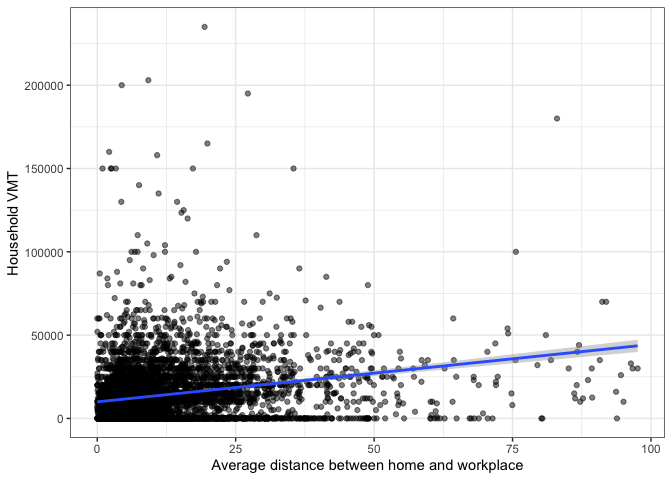
But consider the plot below, showing the same
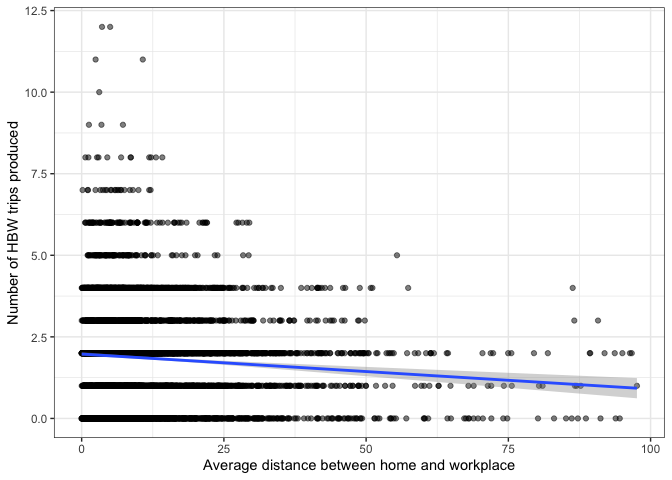
# Poisson Model
A better option would be to predict a probability that each household will produce a certain discrete number of trips. One way to do this is with a Poisson regression model. In this model, an analyst predicts the mean of a Poisson distribution with a regression equation (instead of a line). The Poisson distribution is:
where the probability of a discrete outcome
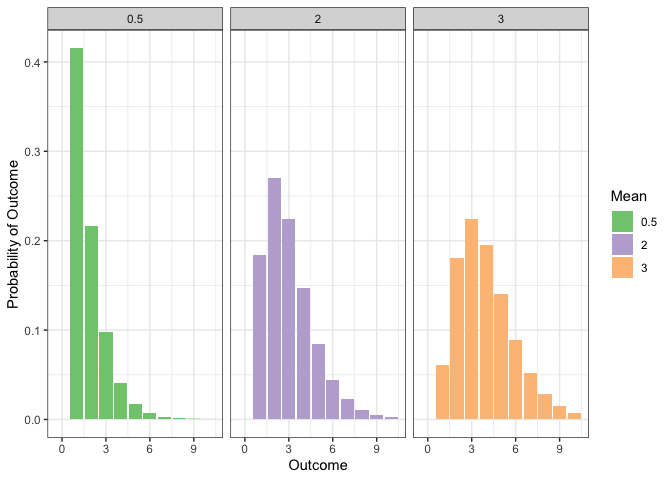
A Poisson regression model allows attributes of an observation to affect the
value of the mean. So instead of
| Linear | Poisson | |
|---|---|---|
| (Intercept) | -0.106 | -0.570*** |
| (-1.625) | (-13.865) | |
| avg_workdist | -0.010*** | -0.006*** |
| (-6.851) | (-7.070) | |
| wrkcount | 1.168*** | 0.665*** |
| (29.000) | (28.801) | |
| hhvehcnt | 0.147*** | 0.089*** |
| (5.626) | (5.925) | |
| Num.Obs. | 5533 | 5533 |
| R2 | 0.185 | |
| R2 Adj. | 0.185 | |
| AIC | 19111.6 | 17871.7 |
| BIC | 19144.7 | 17898.1 |
| Log.Lik. | -9550.813 | -8931.830 |
| F | 419.097 |
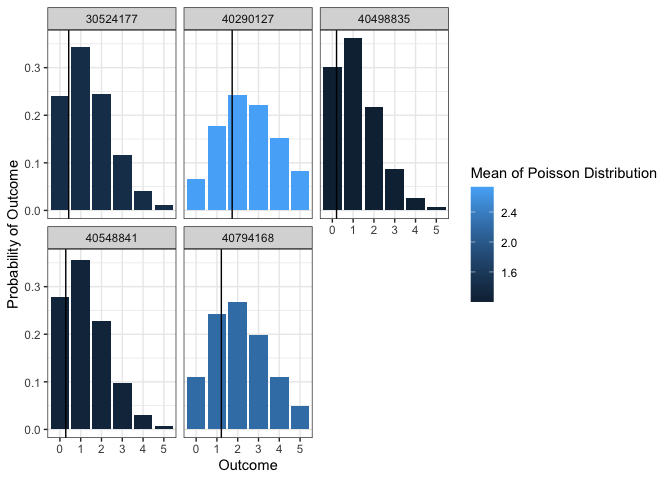
Of course, this is just an average. In a trip-based model, this average for each household might be sufficient. But you could also simulate a discrete choice for each person. The plot below shows the probability of a certain number of trips made by a sample of households, alongside what the predicted Poisson mean was. Households with a higher predicted mean have a higher probability of making more trips.
# Negative Binomial Model
The Poisson model assumes that the mean and standard deviation of the distribution are the same. This can be a bad assumption, because it forces the distribution to spread out when the mean is higher. The negative binomial model relaxes this assumption, and might be useful in some contexts.
# Hurdle Model
The Poisson and negative binomial models assume the same distribution across all outcomes; this might not be desirable if the number of zeros is high or low for some structural reason. For example, owning zero vehicles is very different from owning one or two. A hurdle model breaks the distribution into two different components:
- A binomial model determines the probability of choosing zero versus a positive number.
- A poisson or negative binomial model (with zero removed) determines the probability of a specific positive number, conditioned on the previous model.