Model Validation and Reasonableness Checking/Mode Choice
# Mode Choice/ Vehicle Occupancy
This chapter discusses the validation of model components related to mode choices21 including estimation of vehicle occupancy levels. In activity-based models, relevant model components include tour- and trip-level mode choice models.
The most common formats for mode choice models are the multinomial and nested logit models. The inputs always include level of service variables such as time, cost, and the number of transit transfers. Other input variables may also be used, including socioeconomic characteristics of travelers or households and characteristics of production or attraction zones. Mode choice is usually modeled separately for each trip or tour purpose.
The alternatives for logit mode choice models are the travel modes. Auto modes often include classifications by vehicle occupancy level, with the highest level being determined by analysis needs such as the need to distinguish between two and three person carpools for high occupancy vehicle (HOV) lane analysis. Some models also classify auto submodes by whether or not the path includes paying a toll. A simple model could have only one or two (drive alone versus carpool) auto submodes; a more complex model could have many auto submodes (drive alone-toll, drive alone-no toll, two person carpool-toll, etc.).
Transit modes are usually divided into walk access and auto access submodes if there are a significant number of transit riders who drive to or are dropped off at transit stops. Some models further separate the auto access submodes into park-and-ride and kiss-and-ride (drop-off) submodes. In areas with significant transit service that is not local or line-haul bus, the transit submodes may be further disaggregated into submodes defined by technology or operating characteristics. These submodes may include local bus, express bus, light rail, subway/elevated, commuter rail, and other modes. A more complex model might include many transit submodes defined by access mode and technology/ operation.
Nonmotorized modes include walking and bicycling. In nearly all cases, there is simply a single nonmotorized mode or two distinct modes, representing walk and bicycle.
Some regions might specify more complex travel models than are warranted based on existing travel choices represented in a travel survey. This is often the case for regions that anticipate testing new alternatives in the future. For example, a region that does not have HOV lanes in a base year might specify a model that stratifies the auto mode by group size rather than simply modeling drive alone and carpool trips. This would provide the capability for testing alternative carpool lane treatments. Likewise, an area without fixed guideway transit service may specify mode models that include walk and drive access (to estimate park-and-ride lot usage) and fixed guideway submodes in order to test future alternatives.
Vehicle occupancy estimates may be obtained from the mode choice model if drive alone and carpool submodes are modeled separately. However, in these cases, it is always necessary to make assumptions about vehicle occupancy for the submode representing the highest occupancy level. For example, if a model has three auto submodes – drive alone, two person carpool, and three or more person carpool – the vehicle occupancy level for the three or more person carpool mode must be assumed. The highest occupancy level, which may vary by trip or tour purpose, is typically estimated from household survey data. If there are not separate auto submodes for different occupancy levels, a separate vehicle occupancy model, usually separated by trip/tour purpose, may be applied to convert auto person trips to vehicle trips. This may be a simple model with inputs based on trip length.
This chapter is organized as follows. Validation of mode choice models is discussed in Checks of Mode Choice Model Results. Checks of Vehicle Occupancy Results presents the validation of vehicle occupancy levels, whether they are estimated in the mode choice model or through other means.
# Checks of Mode Choice Model Results
The outputs of mode choice models are trip tables, tours, or trips by mode. Since the inputs indicate the origins and destinations of the tours or trips, the geographic locations of the results are known. This allows geographic segmentation of the results for validation.
# Sources of Data
The main sources of data for validation of mode choice models include the following:
- Transit ridership counts – Transit ridership counts have the best information on the total amount of travel by transit, usually at the route level. It is important to recognize, however, that ridership (boarding) counts represent "unlinked trips," meaning that a person is counted each time he or she boards a new transit vehicle. So a trip that involves transit transfers is counted multiple times. Mode choice models generally consider "linked trips," where a trip including transfers counts as only one trip. Information on transfer rates is required to convert unlinked trips to linked trips; such information generally is obtained from transit on-board surveys.
- Transit rider survey – A transit rider survey (typically an on-board survey) is an invaluable source of information for validation of the transit outputs of mode choice models but may have also been a data source for model estimation. A wealth of information that cannot be obtained from transit counts is available from on-board surveys, including:
- Transit trip origin-destination patterns by trip purpose;
- Access modes;
- Transit paths (surveys should ask riders to list all routes used in order for the linked trip);
- Transit submodes used (e.g., bus, light rail);
- Transit transfer activity; and
- Characteristics of the surveyed riders and their households. It should be noted that transit on-board surveys usually provide data only for individual transit trips, not tours, and so their use in estimating transit travel in tour-based models is limited.
- Household travel/activity survey – If such a survey is available, it may have also been a data source for model estimation although data from other sources such as transit on-board surveys may also have been used in model estimation. The household survey is the best source for information on nontransit travel data since the number of observations for transit travel is usually small. The expanded household survey data can be used to produce observed mode shares for nontransit travel by purpose for a number of geographic and demographic market segments.
- Census data – The Census Transportation Planning Package (CTPP) contains information on modes for work travel. As discussed in Sources of Data (Distribution), the Census Bureau now uses the American Community Survey (ACS), which is conducted continuously, to collect data on work location and travel (among other items). Sources of Data (Distribution) also discusses how work travel is treated differently in the ACS compared to travel models. The CTPP data are more consistent with tour-level work travel than trip level; however, data on travel only in the home to work direction are available.
- National sources – National data sources include the National Household Travel Survey (NHTS), NCHRP Report 365, Travel Estimation Techniques for Urban Planning, which is being updated (the update is expected to be available in 2010), and other documents (e.g., TCRP Report 73, Characteristics of Urban Travel Demand).
- Highway usage data – Data on highway usage such as toll road and high-occupancy vehicle lane use would be helpful validation data for models that include related modal alternatives.
# Aggregate Checks (Mode Choice)
The most basic aggregate checks of mode choice model results are comparisons of modeled trips or tours by mode, or mode shares, to observed data by market segment. Market segments include trip or tour purposes as well as demographic segments, such as income or vehicle availability levels, and geographically defined segments.
Mode choice models are typically applied using trip tables (or their tour-based equivalents) as inputs. The mode choice model's results, therefore, are shares of the total trip table for each market segment that use each of the modal alternatives. Validation of the model's aggregate results involves checking the shares for the model's base year scenario results against observed mode shares.
A household survey is the only comprehensive data source covering all modes, and therefore is the only source for mode shares. However, mode shares for modes that are used relatively infrequently – notably transit modes – as well as mode shares for relatively small segments of the population (such as members of zero-vehicle, high income households) cannot be accurately estimated from household surveys due to small sample sizes.22 While it may be problematic to find an alternate source for some segments or modes (such as bicycle travel), transit trips and shares by segment may be estimated using data sources including ridership counts and transit rider surveys.
Transit ridership counts provide estimates of total transit trips, not mode shares. To convert these trips to shares, an estimate of the total trip table for each market segment is needed. Assuming good validation of the trip generation and distribution components (or their tour-based equivalents), the trip table outputs from the trip distribution model can provide this information. Basically, the transit trips by submode, access mode, trip purpose, and other segmentation level, segmented using the transit rider survey data, can be subtracted from the total trips represented in the trip table to obtain estimates of "observed" nontransit trips. The nontransit trips can be separated into trips by individual mode (auto and nonmotorized submodes) using information from the household travel survey. An example of how this could be done is presented below.
# Example for Estimating Observed Travel By Mode
Figure 7.1 shows a method for estimating observed travel by mode. Say that a trip-based mode choice model is to be validated for a market segment defined geographically (a particular corridor), temporally (a.m. peak period) and demographically (the lowest income group). It is assumed that the trip generation and trip distribution steps are segmented by time period and income group, for each trip purpose. Finally, say that the model has four modes: auto, transit-walk access, transit-auto access, and nonmotorized.
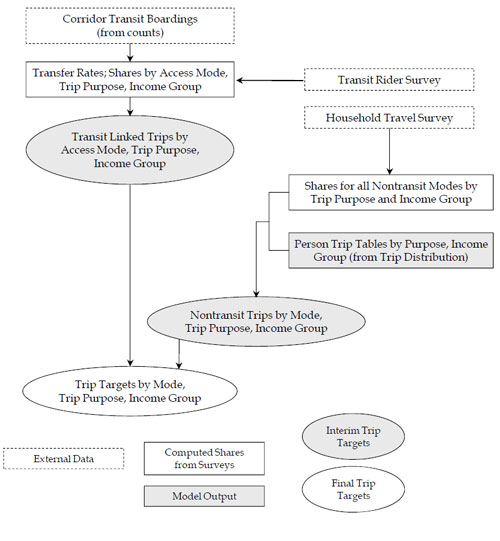
Transit-walk access mode – The transit ridership counts for the corridor for the a.m. peak period are obtained. These counts, which represent boardings, are adjusted using information from on-board survey data to represent "linked" trips (where a trip with a transfer is not counted twice), and the linked trips are separated by trip purpose. The share of transit trips that are walk access is estimated from the on-board survey data, as is the share of trips made by the lowest income group. (Note that this need not be a sequential process; the adjustments for transfers, trip purpose, access mode, and income level could be done in a combined way using the survey data.) The result is an estimate of a.m. peak period transit-walk access trips made by low income travelers in the corridor, stratified by trip purpose.
Transit-auto access mode – These trips are estimated in essentially the same way as the transit-walk access trips, except that transit-auto access travel data from the on-board survey are used. The result is an estimate of a.m. peak period transit-auto access trips made by low income travelers in the corridor, stratified by trip purpose.
Nonmotorized trips – The transit trips by purpose are subtracted from the total trips made by low income residents in the a.m. peak period the corridor, which are known from the outputs of trip distribution. The share of nonmotorized trips among nontransit trips for this market segment can be obtained from the household travel survey data. The result is an estimate of a.m. peak period nonmotorized trips made by low income travelers in the corridor, stratified by trip purpose.
Auto trips – The remaining trips in the corridor for this market segment must be by auto. The result is an estimate of a.m. peak period auto trips made by low income travelers in the corridor, stratified by trip purpose.
The results of the mode choice model for the segment can be compared to these estimates of observed travel for aggregate model validation. However, it is also a good idea to estimate results for the other segments – the other income groups for the time period – in the corridor and evaluate all the estimates of observed travel for reasonableness prior to performing the aggregate model checks. It might also be wise to stratify the estimates by interchange distance since nonmotorized trips are likely to vary substantially by distance.
# Other Considerations
It is common practice to compare overall mode choice model results to the observed data for the region. It is important to recognize that this type of regional check is not sufficient to determine that the mode choice model is validated, any more than it would be sufficient to validate a highway assignment model simply by comparing total regional vehicle miles traveled (VMT) to observed VMT. Aggregate validation must also be performed for all relevant market segments for which information can be obtained.
The mode choice model validation process is tied in with the transit assignment validation process, which is described in Transit Assignment Checks. Any calibration of the transit assignment process may lead to model changes that affect mode choice, whether they are network changes, revisions to path building or skimming, or other changes to the model. The mode choice models cannot be considered validated until the transit assignment model has also been validated.
# Transit Trip Lengths
If observed data on transit trip lengths are available, modeled transit trip lengths should be compared to the observed data. While this is a check of both trip distribution and mode choice, the mode choice model must be run before this check can be performed.
Data on transit trip lengths is usually obtained from transit rider surveys. There are two levels at which observed transit trip length data may be available:
- For the in-vehicle portion of transit trips (stop to stop); and
- For entire trips (origin to destination).
Modeled trip lengths can be obtained for either level although the analyst should be careful to ensure that the model results are consistent with the observed data. For example, say a commuter rail survey yields data on the average length of trips on commuter rail. In this case, for modeled trips that include both commuter rail and bus segments, the length of the commuter rail segment must be considered when comparing to the observed data.
At either level, it is worthwhile for transit trip length comparisons to be segmented using available variables. If the survey data source can provide statistically significant information on trip lengths by trip purpose, traveler/household characteristics (e.g., income level), or subregional geography, it makes sense to perform the comparisons by market segment.
The increasing use of automated passenger counters (APCs) by transit operators might provide an alternate source of data for estimating the in-vehicle portion of observed transit trip lengths. Specifically, if the passengers on-board the transit vehicles between stops are known, the total passenger-miles of travel (PMT) can be estimated. The PMT divided by the total observed boardings provides an estimate of average passenger trip lengths for unlinked trips. This value could be estimated for the region, by service type, by corridor, or by route. Average passenger trip lengths determined using this process can be stratified only by type of service. Stratification by trip purpose or by passenger socioeconomic stratum is not possible.
# Disaggregate Checks (Mode Choice)
As discussed in Recommended Model Validation Approach, in disaggregate validation, model predictions are compared with observed data to reveal systematic biases. Disaggregate checks are appropriate for estimated models, as opposed to transferred models where the estimation data set would not be available. Logit models are disaggregately estimated (one record per trip/activity), and therefore disaggregate validation should be performed when logit mode choice models are estimated, along with the aggregate checks described above.
Generally, disaggregate validation is performed by applying the model using a data set with known choice results (such as a revealed-preference survey data set) and checking the results by one or more segmentation variables. Examples of segmentation variables include:
- Income level;
- Vehicle availability level;
- Geographic segmentation (e.g., counties, area types); and
- Trip length segments.
As discussed in Disaggregate Checks (Distribution), disaggregate validation of a model ideally should be performed using a data set that is independent of the data set used for model estimation. However, most urban area household travel surveys have such small sample sizes that the entire data set is needed for model estimation and so there is no independent model estimation data set available for validation. This is especially true for mode choice models, where the household survey itself is often inadequate for model estimation due to low incidence of transit travel.
Limited disaggregate validation can be performed using the same data set used for model estimation, but reporting the results by market segment. Logit model estimation software has the capability to apply the estimated model to a data set in the same form as the estimation data set. For example, a logit mode choice model could be applied to the data set used for estimation but the results may be reported by vehicle availability or income level. It might be found, for example, that transit with auto access is being chosen too often in the model by households with zero vehicles.
Table 7.1 presents an example of disaggregate model validation. This model has five modes, and the results of the application of the estimated model to the estimation data set are reported by vehicle availability level. The "number chosen" represents the choices in the observed data while the "number predicted" represents the model application results. A number predicted that is greater than the number chosen is shown in italics while the asterisks represent the number of standard deviations beyond one that the predicted number differs from the chosen (e.g., one asterisk means that the difference between the number chosen and number predicted is between one and two standard deviations).
Generally, it is desirable to see a good match between the number predicted and the number chosen for all cells. (In the format shown in Table 7.1, this would be represented by a small number of asterisks.) Where there is not a good match, patterns of underestimation or overestimation of demand should be noted. For example, in Table 7.1, the model underestimates nonmotorized demand, but the underestimation is greater for lower vehicle availability levels. One might consider adding a variable representing vehicle availability or revising coefficients of such variables to address this issue. Transit use is overestimated although the sample sizes for the individual vehicle availability levels are very small, making analysis of trends across vehicle availability levels problematic. It is best to perform disaggregate validation multiple times, with different segmentation schemes, to identify the most significant validation issues to address.
</center> | <center>
**1 Vehicle**
</center> | <center>
**2 Vehicles**
</center> | <center>
**3+ Vehicles**
</center> | <center>
**All**
</center> |
|
Nonmotorized
# Criteria Guidelines
There are no applicable criteria guidelines for checks of mode choice. It is desirable to have the aggregate base year mode shares by market segment match the observed data, but it is important to recognize that the "observed" data are created only by combining different data sources such as traffic counts and household and transit on-board survey data, the latter of which represent relatively small samples of the population.
# Reasonableness and Sensitivity Testing (Mode Choice)
# Parameter Estimates
Mode choice model parameters, the coefficients and constants in the utility functions, may be estimated using local data, transferred from another model, or asserted. An important reasonableness check is that all mode choice model parameters should be of reasonable sign and magnitude.
Estimated parameters should be checked not only for reasonableness, but also for statistical significance. A complete set of statistical tests should be performed as part of the model estimation process.23 While this testing is not described in detail here, those checking the reasonableness of estimated parameters should be aware of the statistical significance of the estimates.
It is important to distinguish between generic coefficients, which have the same value for all alternatives, and alternative-specific, or mode-specific, coefficients, which are different for every alternative. Generally, if a variable has the same value for a particular traveler/trip for every alternative (for example, number of autos owned, in a mode choice model), it must be mode-specific (with the coefficient equal to zero for one alternative). It is possible to constrain the coefficients for mode-specific coefficients to be the same for a group of alternatives, but not for all alternatives. A generic coefficient may be used when the value of the variable is not the same for all alternatives (and may be viewed as different variables for each mode). For example, in-vehicle time has different values depending on whether the mode is auto, transit, etc.
For parameters that are mode-specific, the sign should be positive if the variable represents a characteristic that is positively correlated with the use of the mode, and vice versa. For example, if a transit mode utility has a variable that is equal to one if the household owns no vehicles and zero otherwise, the variable should have a positive coefficient (assuming that auto mode utilities do not also have this variable).
It is important to recognize that the values of mode-specific coefficients are relative to those in the utility functions for other modes. The correct sign for a coefficient may be positive if the coefficient of one mode is zero (this is often referred to as the "base" mode) while the correct sign may be negative with a different base mode. An example for a multinomial logit model with three modes is shown in Table 7.2.
</center> | <center>
**Mode B**
</center> | <center>
**Mode C**
</center> |
| 1 | 0 | 1.5 | -1.0 | | 2 | -1.5 | 0 | -2.5 | | 3 | 1.0 | 2.5 | 0 |
Level of service coefficients should always be negative in sign since higher values of the variables (time, cost) for a mode represent a worse level of service. These coefficients represent the sensitivity of mode choice to particular components of level of service. Therefore, they might be expected to have similar values for all mode choice models, at least those structured similarly, since it would seem unlikely that travelers in one urban area are far more or less sensitive to, say, wait time than they are in another area.
Some studies have shown consistency among parameter estimates for various mode choice models in the U.S. Tables 7.3 through 7.5 compare parameters from models estimated from the late 1970s through 1990s.24 The coefficients for the different models show some consistency, especially for time variables in home-based work models, but also some significant differences. It is unknown how much the differences in coefficients are due to actual differences in travel behavior across different urban areas (and years), and how much are due to model estimation related issues. Many of the models reviewed contained a variety of other variables whose presence in the models could be affecting the estimated values of level of service coefficients. It is important to consider the effects of other variables in the model when evaluating the reasonableness of model coefficients.
</center> | <center>
**Auto IVT (Min)**
</center> | <center>
**Auto OVT (Min)**
</center> | <center>
**Auto Operating Cost (\$)**
</center> | <center>
**Parking Cost (\$)**
</center> | <center>
**Transit IVT (Min)**
</center> | <center>
**Transit Walk Time (Min)**
</center> | <center>
**Transit Wait Time (Min)**
</center> | <center>
**Transit Transfer Time (Min)**
</center> | <center>
**Transit Cost (\$)**
</center> |
| Compositea | | -0.025 | -0.050 | -0.400 | -1.200 | -0.025 | -0.050 | -0.050 | -0.050 | -0.500 | | Dallas | 1984 | -0.030 | -0.055 | -0.460 | -1.160 | -0.030 | -0.055 | -0.055 | -0.055 | -0.460 | | Denver | 1985 | -0.018 | -0.093 | -0.350 | -0.950 | -0.018 | -0.054 | -0.028 | -0.059 | -0.440 | | Detroit | 1965 | -0.046 | -0.260 | -0.650 | -0.650 | -0.046 | -0.064 | -0.117 | -0.038 | -0.650 | | Los Angeles | 1991 | -0.021 | | -0.296 | -0.296 | -0.021 | -0.053 | -0.053 | -0.053 | -0.296 | | Milwaukee | 1991 | -0.016 | -0.041 | -0.450 | -0.450 | -0.016 | -0.041 | -0.041 | -0.041 | -0.450 | | Philadelphia | 1986 | -0.042 | | -0.260 | -0.260 | -0.011 | -0.032 | -0.051 | -0.051 | -0.115 | | Pittsburgh | 1978 | -0.047 | -0.069 | -2.100 | -2.100 | -0.047 | -0.069 | -0.069 | -0.069 | -2.100 | | Portland | 1985 | -0.039 | -0.065 | -1.353 | -1.353 | -0.039 | -0.065 | -0.040 | -0.090 | -1.353 | | Sacramento | 1991 | -0.025 | -0.038 | -0.279 | -0.279 | -0.025 | -0.038 | -0.038 | -0.038 | -0.279 | | St. Louis | 1965 | -0.023 | -0.057 | -1.170 | -1.170 | -0.023 | -0.057 | -0.057 | -0.057 | -1.170 | | Tucson | 1993 | -0.018 | | -0.184 | -0.184 | -0.018 | -0.040 | -0.040 | -0.040 | -0.184 | | Average | | -0.029 | -0.085 | -0.687 | -0.805 | -0.027 | -0.052 | -0.053 | -0.054 | -0.682 |
</center> | <center>
**Auto IVT (Min)**
</center> | <center>
**Auto OVT (Min)**
</center> | <center>
**Auto Operating Cost (\$)**
</center> | <center>
**Parking Cost (\$)**
</center> | <center>
**Transit IVT (Min)**
</center> | <center>
**Transit Walk Time (Min)**
</center> | <center>
**Transit Wait Time (Min)**
</center> | <center>
**Transit Transfer Time (Min)**
</center> | <center>
**Transit Cost (\$)**
</center> |
| Compositea | | -0.008 | -0.020 | -0.800 | -2.000 | -0.008 | -0.020 | -0.020 | -0.020 | -1.000 | | Dallas | 1984 | -0.004 | -0.007 | -0.230 | -0.580 | -0.004 | -0.007 | -0.007 | -0.007 | -0.230 | | Denver | 1985 | -0.012 | -0.076 | -1.310 | | -0.012 | -0.076 | -0.076 | | | | Detroit | 1965 | -0.007 | | -9.960 | -9.960 | -0.007 | -0.011 | -0.018 | -0.018 | -9.960 | | Los Angeles | 1991 | -0.024 | -0.061 | -0.216 | -0.216 | -0.024 | -0.061 | -0.061 | -0.061 | -0.216 | | Milwaukee | 1991 | -0.009 | -0.069 | -1.330 | -1.330 | -0.009 | -0.069 | -0.069 | -0.069 | -1.330 | | Philadelphia | 1986 | -0.020 | | -0.100 | -0.100 | -0.001 | -0.002 | -0.002 | -0.002 | -0.012 | | Pittsburgh | 1978 | -0.017 | -0.079 | -1.450 | -1.450 | -0.017 | -0.079 | -0.079 | -0.079 | -1.450 | | Portland | 1985 | -0.033 | -0.086 | -0.399 | -0.399 | -0.033 | -0.086 | -0.086 | -0.086 | -0.399 | | Sacramento | 1991 | -0.021 | -0.055 | -0.557 | -0.557 | -0.021 | -0.055 | -0.055 | -0.055 | -0.557 | | St. Louis | 1965 | -0.024 | -0.060 | -2.430 | -2.430 | -0.024 | -0.060 | -0.060 | -0.060 | -2.430 | | Tucson | 1993 | -0.024 | | -0.250 | -0.250 | -0.024 | -0.054 | -0.054 | -0.054 | -0.250 | | Average | | -0.020 | -0.068 | -1.855 | -1.855 | -0.018 | -0.053 | -0.054 | -0.054 | -1.845 |
</center> | <center>
**Auto IVT (Min)**
</center> | <center>
**Auto OVT (Min)**
</center> | <center>
**Auto Operating Cost (\$)**
</center> | <center>
**Parking Cost (\$)**
</center> | <center>
**Transit IVT (Min)**
</center> | <center>
**Transit Walk Time (Min)**
</center> | <center>
**Transit Wait Time (Min)**
</center> | <center>
**Transit Transfer Time (Min)**
</center> | <center>
**Transit Cost (\$)**
</center> |
| Compositea | | -0.020 | -0.050 | -0.600 | -1.600 | -0.020 | -0.050 | -0.050 | -0.050 | -0.800 | | Dallas | 1984 | -0.012 | -0.024 | -0.440 | -0.700 | -0.012 | -0.024 | -0.024 | -0.024 | -0.440 | | Denver | 1985 | -0.013 | -0.033 | -1.330 | | -0.013 | -0.033 | -0.033 | | | | Detroit | 1965 | -0.016 | -0.355 | -4.670 | -4.670 | -0.016 | -0.023 | -0.039 | -0.039 | -4.670 | | Los Angeles | 1991 | -0.050 | -0.126 | -0.453 | -0.453 | -0.050 | -0.126 | -0.126 | -0.126 | -0.453 | | Milwaukee | 1991 | -0.011 | -0.074 | -0.310 | -0.310 | -0.011 | -0.074 | -0.074 | -0.074 | -0.310 | | Philadelphia | 1986 | -0.004 | -0.009 | -0.046 | -0.114 | -0.007 | -0.017 | -0.017 | -0.017 | -0.086 | | Pittsburgh | 1978 | -0.012 | -0.195 | -3.050 | -3.050 | -0.012 | -0.195 | -0.195 | -0.195 | -3.050 | | Portland | 1985 | | -0.127 | | | | -0.127 | -0.127 | -0.127 | | | Sacramento | 1991 | -0.035 | -0.082 | -1.103 | -1.103 | -0.035 | -0.082 | -0.082 | -0.082 | -1.103 | | St. Louis | 1965 | -0.023 | -0.058 | -2.350 | -2.350 | -0.023 | -0.058 | -0.058 | -0.058 | -2.350 | | Tucson | 1993 | -0.014 | | -0.151 | -0.151 | -0.014 | -0.031 | -0.031 | -0.031 | -0.151 | | Average | | -0.020 | -0.128 | -1.517 | -1.525 | -0.021 | -0.081 | -0.083 | -0.083 | -1.522 |
It is important to consider the coefficients not only individually, but also the relationships between them. In nearly all mode choice models, coefficients for variables representing out-of-vehicle time – including wait, walk access/egress, and transfer time – are greater in absolute value than in-vehicle time coefficients. This relationship implies that time spent waiting or walking is considered more onerous than time spent in a vehicle, usually sitting. As Tables 7.2 through 7.4 show, the ratios of out-of-vehicle time coefficients to in-vehicle time coefficients are about 2 to 3 for home-based work trips with some higher values estimated for nonwork trips. (Note that in some models, different components of out-of-vehicle time have different coefficients.)
Another relationship that can be checked is the value of (in-vehicle) time, which is represented by the ratio of the in-vehicle time coefficient to the cost coefficient. Represented in dollars per hour, the values of time range from about $2 to $5 per hour for work trips, and 50 cents to $5 per hour for nonwork trips with a few outliers for each trip purpose and greater variation for nonwork trips. (It should be noted that cost coefficients and values of time represent the specific base years for which the models were estimated, and the tables have not normalized the cost coefficients to represent the same year's dollar value.)
The row labeled "Composite" in Tables 7.2 through 7.4 shows coefficient values derived by Schultz in 199125 as cited by Cambridge Systematics, Inc. and Barton-Aschman Associates, Inc.26 Schultz used coefficients from mode choice models estimated in the 1970s to develop composite coefficients for use in other areas. As Tables 7.2 through 7.4 show, most of the "composite" coefficients are within the range of experience from the more recent models cited in the tables, and many of them are close to the averages of the coefficients shown in the tables.
Schultz's work helped inform the development of guidelines by the Federal Transit Administration (FTA) for ridership forecasts for Section 5309 New Starts projects. At a workshop in June 2006, 27 FTA presented guidelines for mode choice coefficient values, including the following:
- A typical range for the value of the in-vehicle time coefficient for home-based work trips is ‑0.03 and ‑0.02. If the coefficient falls outside the range, FTA says that "some further analysis (is) appropriate."
- In-vehicle time coefficient for nonhome-based trips should approximately be the same as the in-vehicle time coefficient for home-based work trips.
- A typical range for the in-vehicle time coefficient for home-based other nonwork trips is 0.1 to 0.5 times the in-vehicle time coefficient for home-based work trips.
- A typical range for the coefficient of out-of-vehicle time is 2 to 3 times the corresponding coefficient for in-vehicle time. FTA believes that "compelling evidence" is needed to justify ratios outside this range.
If a nested logit mode choice formulation is used, a logsum variable is included in the model specification for each nest of modal alternatives. The coefficients of these variables are estimated or asserted. While there are no specific reasonableness checks of logsum variable coefficients, especially asserted coefficients, the coefficients' validity must be checked with respect to two rules:
- Logsum coefficients must be between zero and one. The coefficients should be statistically different from both zero and one (although statistical significance can be checked only for estimated coefficients, not for asserted coefficients).
- The logsum coefficient for a nest should be lower than the logsum coefficient for any higher level nest of which the nest is a component.
Mode-specific constants are also model parameters that should be checked for reasonableness. Checks of constants are discussed in Troubleshooting Strategies (Mode Choice).
# Sensitivity Testing
Sensitivity testing can be performed for mode choice models by varying model inputs and checking results for reasonableness. Model inputs that can be varied include level of service variables used in the trip distribution model (time/speed and cost) and the demographic- or zone-level variables that are used as model inputs. Some example tests include:
- Increasing or decreasing highway or transit travel times by a fixed percentage regionwide;
- Increasing/decreasing parking costs in the CBD by a fixed percentage;
- Increasing/decreasing headways on selected transit routes or submodes by a fixed percentage or amount;
- Increasing/decreasing fares on selected transit submodes by a fixed percentage;
- Changing development patterns for forecast years by moving projected new activity among different parts of the modeled region (e.g., from suburbs to small urban centers or from outlying areas to infill); and
- Reallocating the number of households by income level for a forecast year.
The resultant changes in demand due to changes in a model input variable reflect the sensitivity to the variable; the sensitivity level is determined by the coefficient of the variable in the utility function. Simple "parametric" sensitivity tests can be performed by introducing small changes in the input variable or in the parameter itself and checking the results for reasonableness.
The changes in demand for a modal alternative (or group of alternatives) with respect to a change in a particular variable can be expressed as arc elasticities. Arc elasticity may be calculated as:
- η = Arc elasticity;
- q1 = Value of result (demand) for base condition;
- q2 = Value of result (demand) for change condition;
- p1 = Value of variable for base condition; and
- p2 = Value of variable for change condition.
While there are some rules of thumb for what constitute reasonable elasticities,28 there are not yet specifically defined ranges of reasonable elasticities. Generally, experience has shown that elasticities of transit demand with respect to level of service variables are usually well under 1.0 in absolute value. The "Simpson-Curtin Rule" indicates that the elasticity of transit demand with respect to fare is about ‑0.3. It is important to recognize that since the logit formulation is nonlinear, the elasticities of modal demand are not constant. The elasticity calculated for one particular "point" (say, a specific market segment defined geographically, demographically, and temporally) will not be equal to the elasticities computed at other points.
# Troubleshooting Strategies (Mode Choice)
Issues discovered during the model checks described in Sections Aggregate Checks (Mode Choice), Disaggregate Checks (Mode Choice), and Reasonableness and Sensitivity Testing (Mode Choice) may imply errors in mode choice model parameters, input data (networks/skims or trip tables), or highway or transit path building procedures. Table 7.6 shows some of the typical problems that may be evident from these tests. Note that while four-step model terminology (e.g., "trip distribution") is used in the table, if a mode choice model that is part of an activity-based model system is being validated, the corresponding components (e.g., tour- and trip-level destination choice) should be used.
The types of actions shown in Table 7.6 show some similar themes for each mode. If the modeled base year demand for a mode within a market segment (defined by a combination of geographic, temporal, and/or demographic segmentation) is too high or too low compared to the observed demand estimate, it is important to make sure that the total demand for the segment is correct. For example, if a corridor has too much modeled transit demand for the a.m. peak period, the total demand in the corridor should be checked. Say the observed transit demand estimate is 1000 and the total modeled demand for the segment is 2000. The analyst should determine whether it is reasonable for the transit share to be 50 percent for the segment. If not, and the observed transit demand estimate is accurate, then it is likely that the total modeled demand from the trip distribution process is inaccurate. In this case, calibration procedures focused on mode choice will not only be ineffective, but they may also possibly be counterproductive, introducing counterbalancing errors to offset the trip distribution error. While this may "fix" the base year results, sensitivities for future year forecasts may be adversely impacted.
</center> |
| 1. Transit demand for specific market segments is too high or low | - Check trip distribution to determine if overall travel in the market is correct
- Check implied transit share for market (observed transit demand divided by the total travel in market from trip distribution) to determine if it is reasonable
- Recheck transit skim data related to the market (for appropriate geographic scope and time periods)
- Consider revisions to logit model structure
- Consider adding or removing indicator variables related to the market, or adjusting the coefficients of existing indicator variables (see discussion below)
- Consider revisions to alternative specific constants (see discussion below) |
| 2. Nonmotorized mode shares for specific market segments are too high or low | - Check trip distribution to determine if overall travel in the market is correct
- Recheck skim data (usually distance skims) related to the market (for appropriate geographic scope and time periods)
- Consider adding or removing indicator variables related to the market, or adjusting the coefficients of existing indicator variables (see discussion below)
- Consider revisions to alternative specific constants (see discussion below) |
| 3. Auto submode (e.g., toll versus nontoll) shares for specific market segments are too high or low (note that vehicle occupancy checks are discussed separately in Checks of Vehicle Occupancy Results) | - Check trip distribution to determine if overall travel in the market is correct
- Check implied mode share for market (observed modal demand divided by the total travel in market from trip distribution) to determine if it is reasonable
- Recheck skim data related to the market (e.g., toll cost skims for toll road corridors, for appropriate geographic scope and time periods)
- Consider adding or removing indicator variables related to the market, or adjusting the coefficients of existing indicator variables (see discussion below)
- Consider revisions to alternative specific constants (see discussion below) |
| 4. Mode choice too sensitive or insensitive to level of service changes | - Adjust parameters for appropriate level of service variables in utility functions |
If the validation issues are found to be most likely associated with the mode choice model, the best calibration method may not immediately be apparent from among several possibilities. The best strategy for addressing the issue might lie in:
- Revisions to input data or the procedures to create them (e.g., skimming);
- Changes to model parameters (utility equation coefficients or alternative specific constants);
- Changes to the model structure (e.g., nesting);
- Changes to modal alternative definition; or
- Changes to market segmentation in the model.
The tests described in Table 7.6 are not intended to be performed in isolation, and an iterative approach to testing may be necessary. For example, consider a model where both modeled transit and modeled nonmotorized mode shares are too low. Adjustments that increase the transit shares may further decrease the nonmotorized mode shares; when calibration actions are taken to increase the nonmotorized mode shares, the transit shares may be affected further. If it is found that overall trip distribution issues are responsible for mode choice validation issues, they will affect all modes.
# Mode-Specific Constants
The interpretation of a mode-specific constant is that it represents the part of the modal utility that is not considered by the variables in the utility function. The variables represent measurable characteristics of the trip/tour, the traveler, and the area on which the trip/tour is made that affect the choice of mode. The constant, therefore, represents the sum of items that affect the choice that are not included in the variables. These items may include reliability, comfort, convenience, safety, and many other factors.
In model estimation, the original values of constants are estimated. The constants can easily be revised so that modeled mode shares match targets. It is evident that the "correct" values for modal constants are unknown since they represent factors affecting choice that could not be quantified sufficiently to be included in other mode variables. It would be incorrect, however, to assume that all validation issues are the result of these unknown factors. As is the case with K-factors, as discussed in Troubleshooting Strategies (Distribution), simple adjustments to modal constants estimated using weighted samples should be considered "a last resort" after all other possible causes for error and calibration adjustments have been considered, and so this is why they are listed as the last items in each box in Table 7.6. Because constants can be revised to provide nearly perfect matches between modeled and observed mode shares, it can be very tempting to revise modal constants to resolve differences in shares without determining whether it is the best method to solve the problem at hand.
It should be noted that mode choice constants that are estimated from nonweighted data sets do not reflect the maximum likelihood estimates of the observed behavior and therefore should be adjusted after model estimation. Similarly, if constants are transferred from another model, they will need to be adjusted since they do not represent the observed behavior in the application context. The "last resort" nature of adjusted constants applies only to models estimated using weighted data sets.
The values of mode-specific constants, whether estimated or revised during calibration, should be checked for reasonableness. One way of doing this is to compare the value of a constant relative to the constants of other modal alternatives to the values of other parameters. For example, the difference between the rail and bus constants could be divided by the in-vehicle time coefficient to express the different in units of minutes of in-vehicle time. If the difference between two constants was -0.5 (with the rail constant higher), and the in-vehicle time coefficient was the same for the two modes and equal to -0.025, the difference in the constants is equivalent to -0.5/-0.025 = 20 minutes of in-vehicle time. This implies that all other things being equal, a traveler would be indifferent between a bus trip and a rail trip that is 20 minutes longer.
The interpretation of differences between constants can be muddied somewhat by modal availability issues. For example, it is common to see transit constants that are so much lower than auto constants that it is implied that a traveler would be indifferent between a transit trip and an auto trip that is several hours longer. However, many travelers may not have the auto mode available while others do not consider transit as a viable mode.
# Market Segment Indicator Variables
Indicator variables, or dummy variables, take values of zero or one depending on whether the trip/tour or traveler belongs to a particular market segment. Indicator variables may include variables that represent:
- Whether the traveler belongs to a particular demographic group (income level, number of vehicles available to household, etc.);
- Whether the trip or tour is to, from, or through a particular type of area, such as the central business district (CBD);
- Whether the trip or tour has a particular characteristic related to the transportation service provided, such as transit transfers or transfer mode; or
- Whether the trip or tour is for a particular subpurpose.
Since the value of the indicator variable is the same for each market segment represented, it effectively changes the constant term for that market segment by the amount of the indicator variable's coefficient. For example, if a mode has a constant of -0.5, and the traveler is a member of a segment with an indicator variable coefficient of 1.0, the effective modal constant for the traveler is +0.5. The set of effective mode-specific constants for a traveler who is a member of one segment might be quite different than the set for a traveler in another segment.
One check of the coefficients of indicator variables that are ordered, such as income or vehicle availability levels, is that they have a logical progression in the utility of a mode. For example, if there were variables representing households with 0 vehicles, 1 vehicle, 2 vehicles, and 3 or more vehicles, one would usually expect that the coefficient of the 0-vehicle variable in the utility of a mode such as bus with walk access would be the highest of the four, with the coefficients decreasing as the vehicle availability level increases.
There might be some modes for which the highest coefficient might not be representing one of the extreme category values. For example, a "bus with auto access mode" might have a higher coefficient for 1-vehicle households than for 0, 2, or 3+ vehicle households. In such a case, however, the coefficients should be consistently decreasing from the highest value, or increasing from the lowest, on both sides of the maximum (or minimum). If the 1-vehicle coefficient is highest, then the 3+ vehicle coefficient should be lower than the 2-vehicle coefficient.
It is important to recognize that indicator variables, especially those that represent categories of continuous or near-continuous variables, such as area types or income levels, may be susceptible to the "cliff" problem described in Network Skims and Path Building. A small change in income or a change in trip origin/destination across an area type boundary could result in a large change in utility for a mode. It is better to use continuous variables where possible although it is not always feasible – for example, the survey data used for model estimation or validation may have reported income only for a small number of categories.
It is just as easy to revise coefficients of indicator variables as it is to revise mode-specific constants, and it is just as tempting to make such revisions to attempt to match aggregate observed mode shares for specific market segments by doing so. It is therefore also considered a "last resort" to make such changes in model calibration.
# Forecasting Checks (Mode Choice)
Mode choice forecasts should be compared to base year estimates for reasonableness. Specifically, mode shares by market segment as well as overall regional shares for the forecast year should be compared to the base year. As is the case with the aggregate checks described in Aggregate Checks (Mode Choice), market segments should include trip or tour purposes as well as demographic segments, such as income or vehicle availability levels, and geographically defined segments.
It is not necessarily the case that forecasted mode shares should be similar to modeled base year shares. The most obvious reason for differences might be changes to the transportation system in the forecast year, such as new or extended (in space or time) transit service that would increase transit mode shares. However, it is equally important to consider the effects of changes in land use patterns or demographic changes for residents of the modeled region. For example, if new development is concentrated in outlying areas not served by transit, regional mode shares may decrease while mode shares in the part of the region served by transit remain stable. If income or vehicle availability levels are projected to increase in the future, transit shares may decline.
By performing the aggregate comparisons for a variety of segmentation schemes, it should be possible to obtain a "picture" of the reasons for changes in forecasted mode shares. The examples above demonstrate the value of performing these checks for a comprehensive set of segmentation schemes.
Some checks may reveal an issue with the mode choice model that might require additional testing with the base year scenario. For example, say that the transit share declines substantially while income and vehicle availability increase slightly. This may indicate that the model is too sensitive to one or both of these variables. Additional sensitivity checks using the base year scenario, where all other variables can be kept constant, could be valuable in identifying the problem and suggesting corrective actions.
As discussed above, the mode choice model validation process is tied in with the transit assignment validation process. It is worthwhile to consider performing forecasting checks of both mode choice and transit assignment before determining the best actions to take to address any issues identified.
# 7.2 Checks of Vehicle Occupancy Results
Vehicle occupancy levels can be either results of mode choice models where occupancy levels are alternatives (single occupant, two occupants, etc.) or exogenously derived factors applied to auto person trips or tours. In either case, the numbers should be checked for reasonableness and compared to observed data. Usually, vehicle occupancy is considered separately by trip or tour purpose.
It should be noted that even for mode choice models with alternatives corresponding to specific occupancy levels, an exogenously derived factor must be applied to the auto person trips corresponding to the highest occupancy level modeled. For example, if the highest level modeled is "three or more persons," an exogenously derived factor must be used to convert these trips (or tours) to auto vehicle trips (tours). This factor must be greater than or equal to three and reflects an assumed number of vehicles with three persons, four persons, five persons, etc.
Therefore, in mode choice models with separate vehicle occupancy-level alternatives, the shares for each occupancy level should be validated in the same way that other mode choice results are validated, as described in Checks of Mode Choice Model Results, and the exogenously derived factors for the highest levels should be checked as well. For models in which only exogenous derived (i.e., nonmodeled) vehicle occupancy factors are used, the factors derived from other sources are checked during validation.
In activity-based models, the specific definitions of tour-level modes are important in determining vehicle occupancy levels. Most tour-level mode choice models include separate alternatives at least for single occupant and multiple occupant vehicle tours, with some models including separate alternatives for higher numbers of occupants. Most commonly, a tour is defined as single occupant only if there is only one occupant (the driver) for the entire tour. If a passenger is picked up or dropped off during the tour, the tour is defined as multiple occupant. Most activity-based models have an "escort" tour purpose; the single occupant mode is by definition unavailable for escort tours.
# 7.2.1 Sources of Data
The main sources of data for validation of vehicle occupancy levels include the following:
- Household travel/activity survey – If such a survey is available, it may have also been a data source for model estimation. The expanded household survey data can be used to produce observed vehicle occupancy levels by purpose for a number of geographic and demographic market segments.
- Census data – The CTPP, now based on the ACS, contains information on modes for work travel. As discussed in Sources of Data, these data are more consistent with tour-level work travel than trip level, and data on travel only in the home to work direction are available.
- National sources – Perhaps the most comprehensive source for vehicle occupancy data is NHTS. The 2010 update to NCHRP Report 365, Travel Estimation Techniques for Urban Planning, will also provide information on vehicle occupancy levels for specific urban area types.
- Field observations – While observed vehicle occupancy data are usually available only for a few locations, they may be useful in some cases. One example is observed data at external stations, which may be used in models where external person trips are modeled.
# 7.2.2 Aggregate Checks (Occupancy)
The aggregate checks for vehicle occupancy are checks of the shares of person trips or tours falling into each occupancy category, if the categories are modeled as alternatives in mode choice, and checks of the overall vehicle occupancy levels, including the levels for the highest categories appearing as alternatives in the mode choice model.
It is important to understand the correct way to compute vehicle occupancy and to do so consistently for the model results and the observed data to which they are compared. The vehicle occupancy level is obvious at the disaggregate level; it is simply the number of persons in each vehicle. The average vehicle occupancy for a group of travelers, however – say all home-based work trips – may be computed in more than one way. Consider an example where there are six vehicles: three with one person, two with two persons, and one with three persons. This means that three persons are in single occupant vehicles, four are in two occupant vehicles, and three persons are in three occupant vehicles. The shares represented in a mode choice model of person trips would be 30 percent single occupant, 40 percent two occupant, and 30 percent three occupant. This implies an average vehicle occupancy of 2.0, which is clearly incorrect: there are 10 persons in six vehicles, and the actual vehicle occupancy is 1.67.
In other words, the incorrect average vehicle occupancy is obtained when one multiplies the number of person trips for each occupancy level by the occupancy level and divides the sum of these trips by the total number of person trips. The correct method is to estimate the implied vehicle trips by dividing the number of person trips for each occupancy level by the occupancy level and sum the result over all occupancy levels. The average vehicle occupancy level is then computed by dividing the total person trips by the implied vehicle trips. For the example above, the implied number of vehicle trips is given by:
(3 pers trips / 1 pers/veh) + (4 pers trips / 2 pers/veh) + (3 per trips / 3 pers/veh)
which yields 6 implied vehicle trips. The average vehicle occupancy is 10 person trips divided by 6 implied vehicle trips, or 1.67.
In person-based or person trip-based models, person trips or tours are generated and eventually converted to vehicle trips. If a vehicle trip-based model is being used, there is no conversion required; if one wanted to compute the number of person trips from the number of person trips, the vehicle-based occupancy level would be used.
# Occupancy-Level Shares
The most basic check is to compare the modeled base year model shares of trips made by vehicle occupancy, both by trip or tour purpose and for all trips/tours, to observed shares. In most cases the best (or only) source of observed occupancy levels is from the household survey data. The modeled occupancy levels should match the observed data closely as the percentage error in vehicle occupancy results in the same level of error in the number of vehicle trips. For example, if the overall vehicle occupancy level is too low by five percent, the number of vehicle trips is too high by five percent. (It should be noted, of course, that there is error inherent in the observed data, which is based on a sample, even though it is impossible to precisely know the level of error in the survey data set.)
When a sufficient household survey data set is not available, modeled occupancy levels may be compared to representative data from another data set, such as the NHTS. In these cases, of course, the survey data do not truly represent observed data for the modeled area, and so a precise match is not necessary. The comparison represents more of a reasonableness check.
# Average Vehicle Occupancy
Traditionally, average vehicle occupancies have been reported by trip purpose. However, it is important to recognize that the trip or activity purposes of all passengers in a vehicle are not necessarily the same. For example, in one region, the home-based work average vehicle occupancy has been reported as 1.14 persons per vehicle. Such a report is not strictly correct since the trip purposes of the other passengers in the vehicles may not be home-based work. The correct report is that home-based work person trips are made in vehicles with an average of 1.14 persons per vehicle.
Overall vehicle occupancy should be checked for all person-based models, by trip/tour purpose and for all trips/tours. The average vehicle occupancy should be computed by dividing the total person trips for each market segment by the implied number of vehicles used for those trips.
# 7.2.3 Disaggregate Checks (Occupancy)
If a mode choice model with alternatives corresponding to specific occupancy levels has been estimated, disaggregate validation of the logit model should be performed as part of the validation of the estimated model, as described in Disaggregate Checks (Mode Choice).
# 7.2.4 Criteria Guidelines
There are no applicable criteria guidelines for checks of vehicle occupancy.
# 7.2.5 Reasonableness and Sensitivity Testing (Occupancy)
The reasonableness checks for vehicle occupancy are the comparisons to traffic or person trip counts, as discussed in [[#Aggregate Checks (Occupancy)|Aggregate Checks (Occupancy)].
Sensitivity testing of vehicle occupancy can be performed for a mode choice model with alternatives corresponding to specific occupancy levels. The types of tests discussed in Reasonableness and Sensitivity Testing (Mode Choice) can be performed, using available model variables that may affect vehicle occupancy, such as household size and HOV lane travel times.
# 7.2.6 Troubleshooting Strategies (Occupancy)
Table 7.7 shows some typical issues with vehicle occupancy results and suggested strategies for dealing with them.
</center> |
| 1. Modeled vehicle occupancy by trip/tour purpose differs significantly from observed levels. | - Check observed data for errors
- If a mode choice model with alternatives corresponding to specific occupancy levels is being used, check sensitivity to mode choice model input variables and consider adjusting logit model parameters
- Consider adding or removing indicator variables related to the market, or adjusting the coefficients of existing indicator variables (see discussion in Troubleshooting Strategies (Mode Choice))
- Consider revisions to alternative specific constants (see discussion in Troubleshooting Strategies (Mode Choice)) |
| 2. Overall modeled vehicle occupancy differs significantly from observed levels. | - Compare modeled shares of trips/tours by purpose to observed |
# 7.2.7 Forecasting Checks (Occupancy)
Forecasted vehicle occupancy levels and averages should be compared to base year values for reasonableness. In mode choice models with alternatives corresponding to specific occupancy levels, the forecasted vehicle occupancy levels may differ slightly from the base year values due to changes in the values of forecast year input variables, including household size and levels of congestion on general purpose roadways when HOV facilities are present. In models where fixed vehicle occupancy factors are used, there will be no change in vehicle occupancy levels for the segments (such as trip purposes) over which the actors are applied although there might be small changes in overall vehicle occupancy if the relative numbers of trips in each segment change over time.